pca原理
1 PCA目标
设X为$n \times m$的特征矩阵,那么X的列协方差矩阵为:
$$\mathbf{C} = \frac{1}{n}\mathbf{X^T X} $$
设想存在线性投影使得:
$$\mathbf{Y}=\mathbf{XP}$$
$\mathbf{P}$是$m \times m$阶矩阵,那么$\mathbf{Y}$的列协方差矩阵为:
$$\frac{1}{n}\mathbf{Y^T Y} = \frac{1}{n}\mathbf{(XP)^T (XP)} = \mathbf{P^T} (\frac{1}{n}\mathbf{X^T X})\mathbf{P} = \mathbf{P^T C P} $$
PCA基本思想就是找到$\mathbf{P}$对$\mathbf{X}$进行转换,使$\mathbf{Y}$的协方差矩阵只有方差而无协方差(就是要使得$\mathbf{Y}$的协方差矩阵是个对角矩阵),必要的话丢弃小的方差(这需要$\mathbf{P}$为$m \times k$阶矩阵($k<m$)),根据信息理论,这样可以保留大部分信息,丢掉小方差即丢掉信息含量小的特征从而达到降维的目的。
2 PCA的实现
2.1 回顾特征值和特征向量
求特征值特征向量必须是方阵。
我们首先回顾下特征值和特征向量的定义如下:
$$\mathbf{A}\vec{w}=\lambda\vec{w}$$
其中$\mathbf{A}$是$n \times n$矩阵,$\vec{w}$是特征向量,$\lambda$是特征向量对应的特征值。
求出特征值和特征向量有什么好处呢? 就是我们可以将矩阵A特征分解。如果我们求出了矩阵$\mathbf{A}$的
$k$(特征值特征向量的个数与矩阵$\mathbf{A}$的秩相同)
个特征值
$\lambda_1 \ge \lambda_2 \ge \dots \ge \lambda_k$
,以及这
$k$
个特征值所对应的特征向量
$\{\vec{w}_1,\vec{w}_2,\dots,\vec{w}_k\}$
。
如果这
$n$(即特征值特征向量个数$k=n$)
个特征向量线性无关(协方差矩阵是对称矩阵,对称矩阵的特征向量两两正交,因此线性无关),那么矩阵$\mathbf{A}$就可以用下式的特征分解表示:
$$\mathbf{A}=\mathbf{W}\mathbf{\Sigma}\mathbf{W}^{-1}$$
其中$\mathbf{W}$是$n \times n$矩阵,$\mathbf{\Sigma}$是包含所有n个特征值的$n \times n$主对角矩阵。一般我们会把$\mathbf{W}$的这
$n$
个特征向量标准化,即满足
$||\vec{w}_i||_2 =1$
, 或者说
$\vec{w}_i^T\vec{w}_i =1$
,此时$\mathbf{W}$的
$n$
个特征向量为标准正交基,满足
$\mathbf{W}^T\mathbf{W}=\mathbf{I}$
。即
$\mathbf{W}^T=\mathbf{W}^{-1}$
, 也就是说$\mathbf{W}$为酉矩阵。
这样我们的特征分解表达式可以写成
$$\mathbf{A}=\mathbf{W\Sigma W^T}$$
注意到要进行特征分解,矩阵$\mathbf{A}$必须为方阵。那么如果A不是方阵,即行和列不相同时,我们还可以对矩阵进行分解吗?答案是可以,此时我们的SVD登场了。
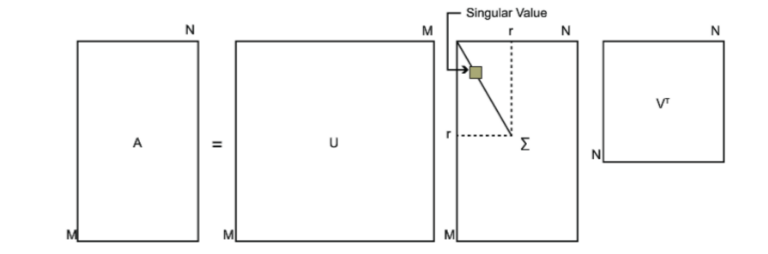
2.2 SVD原理
SVD也是对矩阵进行分解,但是和特征分解不同,SVD并不要求要分解的矩阵为方阵。假设我们的矩阵$\mathbf{A}$是一个
$m \times n$
的矩阵,那么我们定义矩阵$\mathbf{A}$的SVD为:
$$\mathbf{A} = \mathbf{U} \mathbf{\Sigma} \mathbf{V}^T$$
其中$\mathbf{U}$是$m \times m$矩阵,$\mathbf{\Sigma}$是$m \times n$矩阵,除了主对角线上的元素以外全为0,主对角线上的每个元素都称为奇异值,$\mathbf{V}$是$n \times n$矩阵。$\mathbf{U}$和$\mathbf{V}$都是酉矩阵,即满足
$\mathbf{U^TU}=\mathbf{I}, \mathbf{V^TV}=\mathbf{I}$
。下图可以很形象的看出上面SVD的定义:
 那么我们如何求出SVD分解后的
那么我们如何求出SVD分解后的
$\mathbf{U},\mathbf{\Sigma},\mathbf{V}$
这三个矩阵呢?
如果我们将$\mathbf{A}$的转置和$\mathbf{A}$做矩阵乘法,那么会得到
$n \times n$
的一个方阵
$\mathbf{A}^T\mathbf{A}$
。既然
$\mathbf{A}^T\mathbf{A}$
是方阵,那么我们就可以进行特征分解,得到的特征值和特征向量满足下式:
$$(\mathbf{A}^T\mathbf{A})\vec{v}_i = \lambda_i \vec{v}_i$$
这样我们就可以得到矩阵
$\mathbf{A}^T\mathbf{A}$
的$n$个特征值和对应的$n$个特征向量
$\vec{v}$
了。将
$\mathbf{A}^T\mathbf{A}$
的所有特征向量张成一个
$n \times n$
的矩阵$\mathbf{V}$,就是我们SVD公式里面的$\mathbf{V}$矩阵了。一般我们将$\mathbf{V}$中的每个特征向量叫做$\mathbf{A}$的右奇异向量。
如果我们将$\mathbf{A}$和$\mathbf{A}$的转置做矩阵乘法,那么会得到
$m \times m$
的一个方阵
$\mathbf{A}\mathbf{A}^T$
。既然
$\mathbf{A}\mathbf{A}^T$
是方阵,那么我们就可以进行特征分解,得到的特征值和特征向量满足下式:
$$(\mathbf{AA^T})\vec{u}_i = \lambda_i \vec{u}_i$$
这样我们就可以得到矩阵
$\mathbf{A}\mathbf{A}^T$
的m个特征值和对应的m个特征向量
$\vec{u}$
了。将
$\mathbf{A}\mathbf{A}^T$
的所有特征向量张成一个
$m \times m$
的矩阵$\mathbf{U}$,就是我们SVD公式里面的$\mathbf{U}$矩阵了。一般我们将$\mathbf{U}$中的每个特征向量叫做A的左奇异向量。
$\mathbf{U}$和$\mathbf{V}$我们都求出来了,现在就剩下奇异值矩阵
$\Sigma$
没有求出了。由于
$\Sigma$
除了对角线上是奇异值其他位置都是0,那我们只需要求出每个奇异值
$\sigma$
就可以了。
我们注意到:
$$\mathbf{A}=\mathbf{U} \mathbf{\Sigma} \mathbf{V}^T \Rightarrow \mathbf{A}\mathbf{V}=\mathbf{U}\mathbf{\Sigma} \mathbf{V}^T\mathbf{V} \Rightarrow \mathbf{A}\mathbf{V}=\mathbf{U}\mathbf{\Sigma} \Rightarrow \mathbf{A}\vec{v}_i = \sigma_i \vec{u}_i \Rightarrow \sigma_i = \mathbf{A}\vec{v}_i / \vec{u}_i$$
这样我们可以求出我们的每个奇异值,进而求出奇异值矩阵
$\mathbf{\Sigma}$
。
上面还有一个问题没有讲,就是我们说
$\mathbf{A}^T\mathbf{A}$
的特征向量组成的就是我们SVD中的$\mathbf{V}$矩阵,而
$\mathbf{A}\mathbf{A}^T$
的特征向量组成的就是我们SVD中的$\mathbf{U}$矩阵,这有什么根据吗?这个其实很容易证明:
证明$\mathbf{A}^T\mathbf{A}$
的特征向量组成的的确就是我们SVD中的$\mathbf{V}$矩阵:
$$\mathbf{A}=\mathbf{U}\mathbf{\Sigma} \mathbf{V}^T \Rightarrow \\
\mathbf{A}^T=\mathbf{V}\mathbf{\Sigma}^T \mathbf{U}^T \Rightarrow \\
\mathbf{A}^T\mathbf{A} = \mathbf{V}\mathbf{\Sigma}^T \mathbf{U}^T\mathbf{U}\mathbf{\Sigma} \mathbf{V}^T = \mathbf{V}\mathbf{\Sigma}^2\mathbf{V}^T \Rightarrow \\
(\mathbf{A}^T\mathbf{A})\mathbf{V} = (\mathbf{V}\mathbf{\Sigma}^2\mathbf{V}^T)\mathbf{V} = \mathbf{V}\mathbf{\Sigma}^2(\mathbf{V}^T\mathbf{V}) = \mathbf{V}\mathbf{\Sigma}^2
$$
上式证明使用了:
$\mathbf{U}^T\mathbf{U}=I, \mathbf{V}^T\mathbf{V}=I, \mathbf{\Sigma}^T\mathbf{\Sigma}=\mathbf{\Sigma}^2$。
可以看出
$\mathbf{A}^T\mathbf{A}$
的特征向量组成的矩阵的确就是我们SVD中的$\mathbf{V}$矩阵。
证明$\mathbf{A}\mathbf{A}^T$
的特征向量组成的的确就是我们SVD中的$\mathbf{U}$矩阵:
$$\mathbf{A}=\mathbf{U}\mathbf{\Sigma} \mathbf{V}^T \Rightarrow \\
\mathbf{A}^T=\mathbf{V}\mathbf{\Sigma}^T \mathbf{U}^T \Rightarrow \\
\mathbf{A}\mathbf{A}^T = \mathbf{U}\mathbf{\Sigma} \mathbf{V}^T\mathbf{V}\mathbf{\Sigma}^T \mathbf{U}^T = \mathbf{U}\mathbf{\Sigma}^2\mathbf{U}^T \Rightarrow \\
(\mathbf{A}\mathbf{A}^T)\mathbf{U} = (\mathbf{U}\mathbf{\Sigma}^2\mathbf{U}^T)\mathbf{U} = \mathbf{U}\mathbf{\Sigma}^2(\mathbf{U}^T\mathbf{U}) = \mathbf{U}\mathbf{\Sigma}^2
$$
上式证明使用了:
$\mathbf{U}^T\mathbf{U}=I, \mathbf{V}^T\mathbf{V}=I, \mathbf{\Sigma}^T\mathbf{\Sigma}=\mathbf{\Sigma}^2$。
可以看出
$\mathbf{A}\mathbf{A}^T$
的特征向量组成的矩阵的确就是我们SVD中的$\mathbf{U}$矩阵。
进一步我们还可以看出我们的特征值矩阵等于奇异值矩阵的平方,也就是说特征值和奇异值满足如下关系:
$$\sigma_i = \sqrt{\lambda_i}$$
这样也就是说,我们可以不用
$\sigma_i = \mathbf{A}\vec{v}_i / \vec{u}_i$
来计算奇异值,也可以通过求出
$\mathbf{A}^T\mathbf{A}$
的特征值取平方根来求奇异值。
2.3 SVD计算举例
这里我们用一个简单的例子来说明矩阵是如何进行奇异值分解的。我们的矩阵A定义为:
$$\mathbf{A} = \left( \begin{array}{ccc} 0& 1\\ 1& 1\\ 1& 0 \end{array} \right)$$
我们首先求出
$$\mathbf{A^TA} = \left( \begin{array}{ccc} 0& 1 &1\\ 1&1& 0 \end{array} \right) \left( \begin{array}{ccc} 0& 1\\ 1& 1\\ 1& 0 \end{array} \right) = \left( \begin{array}{ccc} 2& 1 \\ 1& 2 \end{array} \right)$$
$$\mathbf{AA^T} = \left( \begin{array}{ccc} 0& 1\\ 1& 1\\ 1& 0 \end{array} \right) \left( \begin{array}{ccc} 0& 1 &1\\ 1&1& 0 \end{array} \right) = \left( \begin{array}{ccc} 1& 1 & 0\\ 1& 2 & 1\\ 0& 1& 1 \end{array} \right)$$
进而求出
$\mathbf{A^TA}$
的特征值和特征向量:
$$\lambda_1= 3; \vec{v}_1 = \left( \begin{array}{ccc} 1/\sqrt{2} \\ 1/\sqrt{2} \end{array} \right); \lambda_2= 1; \vec{v}_2 = \left( \begin{array}{ccc} -1/\sqrt{2} \\ 1/\sqrt{2} \end{array} \right)$$
接着求
$\mathbf{AA^T}$
的特征值和特征向量:
$$\lambda_1= 3; \vec{u}_1 = \left( \begin{array}{ccc} 1/\sqrt{6} \\ 2/\sqrt{6} \\ 1/\sqrt{6} \end{array} \right); \lambda_2= 1; \vec{u}_2 = \left( \begin{array}{ccc} 1/\sqrt{2} \\ 0 \\ -1/\sqrt{2} \end{array} \right); \lambda_3= 0; \vec{u}_3 = \left( \begin{array}{ccc} 1/\sqrt{3} \\ -1/\sqrt{3} \\ 1/\sqrt{3} \end{array} \right)$$
利用
$\mathbf{A}\vec{u}_i = \sigma_i \vec{u}_i, i=1,2$
求奇异值:
$$\left( \begin{array}{ccc} 0& 1\\ 1& 1\\ 1& 0 \end{array} \right) \left( \begin{array}{ccc} 1/\sqrt{2} \\ 1/\sqrt{2} \end{array} \right) = \sigma_1 \left( \begin{array}{ccc} 1/\sqrt{6} \\ 2/\sqrt{6} \\ 1/\sqrt{6} \end{array} \right) \Rightarrow \sigma_1=\sqrt{3}$$
$$\left( \begin{array}{ccc} 0& 1\\ 1& 1\\ 1& 0 \end{array} \right) \left( \begin{array}{ccc} -1/\sqrt{2} \\ 1/\sqrt{2} \end{array} \right) = \sigma_2 \left( \begin{array}{ccc} 1/\sqrt{2} \\ 0 \\ -1/\sqrt{2} \end{array} \right) \Rightarrow \sigma_2=1$$
当然,我们也可以用
$\sigma_i = \sqrt{\lambda_i}$
直接求出奇异值为
$\sqrt{3}$
和1.
最终得到A的奇异值分解为:
$$\mathbf{A}=\mathbf{U\Sigma V^T} = \left( \begin{array}{ccc} 1/\sqrt{6} & 1/\sqrt{2} & 1/\sqrt{3} \\ 2/\sqrt{6} & 0 & -1/\sqrt{3}\\ 1/\sqrt{6} & -1/\sqrt{2} & 1/\sqrt{3} \end{array} \right) \left( \begin{array}{ccc} \sqrt{3} & 0 \\ 0 & 1\\ 0 & 0 \end{array} \right) \left( \begin{array}{ccc} 1/\sqrt{2} & 1/\sqrt{2} \\ -1/\sqrt{2} & 1/\sqrt{2} \end{array} \right)$$
2.4 SVD的一些性质
上面几节我们对SVD的定义和计算做了详细的描述,似乎看不出我们费这么大的力气做SVD有什么好处。那么SVD有什么重要的性质值得我们注意呢?
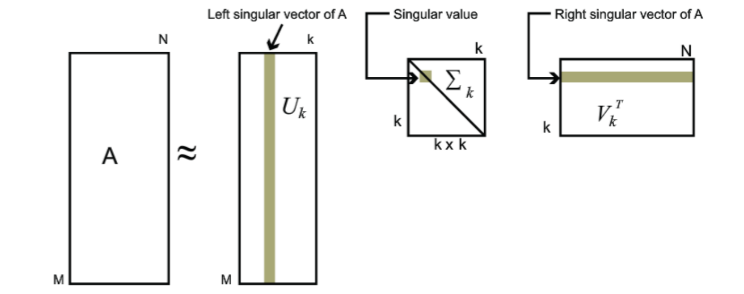
对于奇异值,它跟我们特征分解中的特征值类似,在奇异值矩阵中也是按照从大到小排列,而且奇异值的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上的比例。也就是说,我们也可以用最大的k个的奇异值和对应的左右奇异向量来近似描述矩阵。也就是说:
$$\mathbf{A}_{m \times n} = \mathbf{U}_{m \times m}\mathbf{\Sigma}_{m \times n} \mathbf{V}^T_{n \times n} \approx \mathbf{U}_{m \times k}\mathbf{\Sigma}_{k \times k} \mathbf{V}^T_{k \times n}$$
其中k要比m、n小很多,也就是一个大的矩阵A可以用三个小的矩阵
$\mathbf{U}_{m \times k},\mathbf{\Sigma}_{k \times k} ,\mathbf{V}^T_{k \times n}$
来表示。如下图所示,现在我们的矩阵A只需要黄灰色的部分的三个小矩阵就可以近似描述了(A的前k个最大的特征值参与构建A,对于协方差矩阵,特征值就是方差,代表信息。)。
 由于这个重要的性质,SVD可以用于PCA降维,来做数据压缩和去噪。也可以用于推荐算法,将用户和喜好对应的矩阵做特征分解,进而得到隐含的用户需求来做推荐。同时也可以用于NLP中的算法,比如潜在语义索引(LSI)。下面我们就对SVD用于PCA降维做一个介绍。
由于这个重要的性质,SVD可以用于PCA降维,来做数据压缩和去噪。也可以用于推荐算法,将用户和喜好对应的矩阵做特征分解,进而得到隐含的用户需求来做推荐。同时也可以用于NLP中的算法,比如潜在语义索引(LSI)。下面我们就对SVD用于PCA降维做一个介绍。
2.5 SVD用于PCA
在主成分分析(PCA)原理总结中,我们讲到要用PCA降维,需要找到样本协方差矩阵
$\mathbf{X^TX}$
的最大的d个特征向量,然后用这最大的d个特征向量张成的矩阵来做低维投影降维。可以看出,在这个过程中需要先求出协方差矩阵
$\mathbf{X^TX}$
,当样本数多样本特征数也多的时候,这个计算量是很大的。
注意到我们的SVD也可以得到协方差矩阵
$\mathbf{X^TX}$
最大的d个特征向量张成的矩阵,但是SVD有个好处,有一些SVD的实现算法可以不求先求出协方差矩阵
$\mathbf{X^TX}$
,也能求出我们的右奇异矩阵
$\mathbf{V}$
。也就是说,我们的PCA算法可以不用做特征分解,而是做SVD来完成。这个方法在样本量很大的时候很有效。实际上,scikit-learn的PCA算法的背后真正的实现就是用的SVD,而不是我们我们认为的暴力特征分解。
另一方面,注意到PCA仅仅使用了我们SVD的右奇异矩阵,没有使用左奇异矩阵,那么左奇异矩阵有什么用呢?
假设我们的样本是
$n \times m$
的矩阵$\mathbf{X}$,如果我们通过SVD找到了矩阵
$\mathbf{XX^T}$
最大的k个特征向量张成的
$n \times k$
维矩阵$\mathbf{U}$,则我们如果进行如下处理:
$$\mathbf{Z}_{k \times m} = \mathbf{U}_{k \times n}^T\mathbf{X}_{n \times m}$$
可以得到一个
$k \times m$
的矩阵$\mathbf{Z}_{k \times m}$,这个矩阵和我们原来的
$n \times m$
维样本矩阵$\mathbf{X}_{n \times m}$相比,行数从n减到了k,可见对行数进行了压缩。也就是说,左奇异矩阵可以用于行数的压缩。
相对的,我们如果进行如下处理:
$$\mathbf{Y}_{n \times k} = \mathbf{X}_{n \times m}\mathbf{V}_{m \times k}^T$$
可以得到一个
$n \times k$
的矩阵$\mathbf{Y}_{n \times k}$,这个矩阵和我们原来的
$n \times m$
维样本矩阵$\mathbf{X}_{n \times m}$相比,列数从m减到了k,可见对列数进行了压缩。也就是说,右奇异矩阵可以用于列数的压缩,也就是我们的PCA降维。
2.5 SVD小结
SVD作为一个很基本的算法,在很多机器学习算法中都有它的身影,特别是在现在的大数据时代,由于SVD可以实现并行化,因此更是大展身手。SVD的原理不难,只要有基本的线性代数知识就可以理解,实现也很简单因此值得仔细的研究。当然,SVD的缺点是分解出的矩阵解释性往往不强,有点黑盒子的味道,不过这不影响它的使用。
参考: 1. 刘建平Pinard-奇异值分解(SVD)原理与在降维中的应用。